0x00 Highlight
- 对象粒度访问与页面粒度访问在Overhead和Efficiency存在Trade-off关系(比较全面)
- 四个内存访问模式的分类
- Intel TSX的使用
0x01 Background
之前的工作InfiniSwap, Fastswap, Canvas, Hermit以页面为访问粒度,而AIFM, Kona以对象为访问粒度 (access data at a much finer (object) granularity)。
对象访问粒度具有两个优势:i. 避免I/O放大1, ii. 避免语义丢失错失优化机会。
然而对象访问粒度的性能低一个数量级,其主要原因包括:i. 对象数量大, ii. 访问标记没有硬件支持。
最近的工作Mira基于编译器技术为每个对象选择访问模式,但是是离线的。
Insight: 能否使用在线性能分析识别访问模式,以动态切换访问模式,以达到两个目的:
- 连续分析能识别不同计算阶段或并行线程访问不同数据结构,甚至能识别变化的工作负载;
- 对于不规则模式的程序,对象检索访问能将他们按照时间局部性移动到连续内存空间中,从而提高分页(移出时候的)效率。
0x02 Motivation
逻辑: 云应用的多样访存模式 -> 分页和对象访问粒度对这些访存模式的性能对比 -> 动态路径切换的机遇 => (在线分析的)混合数据平面的必要性
Diverse memory accesses
访存模式由四种原始的模式组合而来(sequential, strided, skewed, and random),受到计算模型/数据模型的驱动。
考虑一个实例:基于MapReduce的应用Metis,运行页面浏览技术(Page View Count)应用。Map阶段,从硬盘中加载URL并且计算哈希值,将哈希值计算进桶里;Reduce阶段,累加这些桶以计算用户数量。呈现如下效果:

具体而言,Map阶段大部分情况下是随机的,但是由于数据集是skewed2的(可以简单理解为统计中非对称的),存在某个桶会挂一个长链表,因此会存在几个顺序访问的范围。而Reduce阶段基本是顺序扫描这些桶,呈现sequential模式。
Granularity-performance tradeoff
比较了AIFM和Fastswap在该应用下的表现,发现AIFM在Map阶段表现优于Fastswap,而在Reduce阶段表现差于Fastswap。这是由于访问模式的不同,对象获取在随机访问下由于Fastswap。
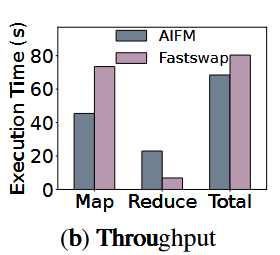
Object eviction cost
为什么对象访问在顺序访问下会差?本文认为,对于具有良好局部性的程序,对象检索的性能不如分页,这是因为与对象分析以及维护基于对象的LRU淘汰机制相关的成本很高。如果没有足够的CPU资源计算这件事情,那么容易发生颠簸。
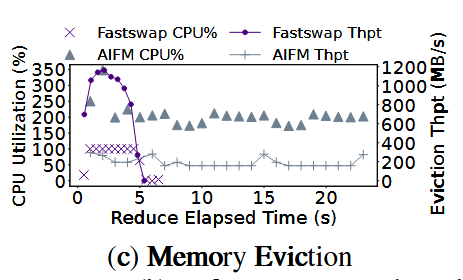
Necessity of online profiling and path switching
为什么(现有的)离线分析表现不佳?i. 数据集不同会对相同代码的访存模式产生较大影响, ii. 对象检索消耗大量CPU资源,而当CPU资源少的时候离线分析的结果难以被应用。
0x03 Design
Challenges and Solutions towards Atlas design
挑战:如何持续地以较低开销分析应用?
具体而言,现在的分页分析虽然高效但是是粗粒度的,对象分析虽然信息充足但是开销过大。考虑一种情况,某个页面虽然访问频率不高,但是其中的某几个对象被频繁访问,那么这个页面应该是热点页面,但是局部性差,因此采用对象粒度访问。
解决:用bitmap维护页面上热点对象(采用read barrier,类似另一篇论文的manual page fault),并且计算热点率。热点率高的页面采用页面访问(局部性好,分页语义和对象语义对齐,采用粗粒度),热点率低的页面采用对象访问(局部性差,采用细粒度)。
挑战:如何动态切换访问模式?
在read barrier的时候检查PSF(path selector flag)标志位。
PSF只决定访问路径,而驱逐路径统一采用基于页面的驱逐。主要是驱逐需要维护LRU,然而基于对象的LRU维护成本高,按照页面的驱逐可以降低成本。然而这样可能导致I/O放大,因此Atlas通过整合对象缓解这个问题。i. fetch对象到同一个页面, ii. 主动迁移对象到连续内存空间,并且对最近访问对象分组到连续页面上以提高局部性。
挑战:两条路径的如何同步?
使用一个同步协议完成(覆盖了所有情况)。
Overview
(没有图欸)
主要设计是基于前面提到的bitmap,论文里记为CAT (card access table),然后计算CAR (card access rate),在页面换出的时候通过CAR计算PSF,在换入的时候读取PSF决定路径。
这个设计在Java里面也有类似的,本文基于AIFM实现的。
Ingress
AIFM里面有一个P位可以检查某个对象是否在远端内存,但是混合数据平面不行。因为Atlas的换出是基于页面的,页面换出的时候去追踪对象标记不太现实。
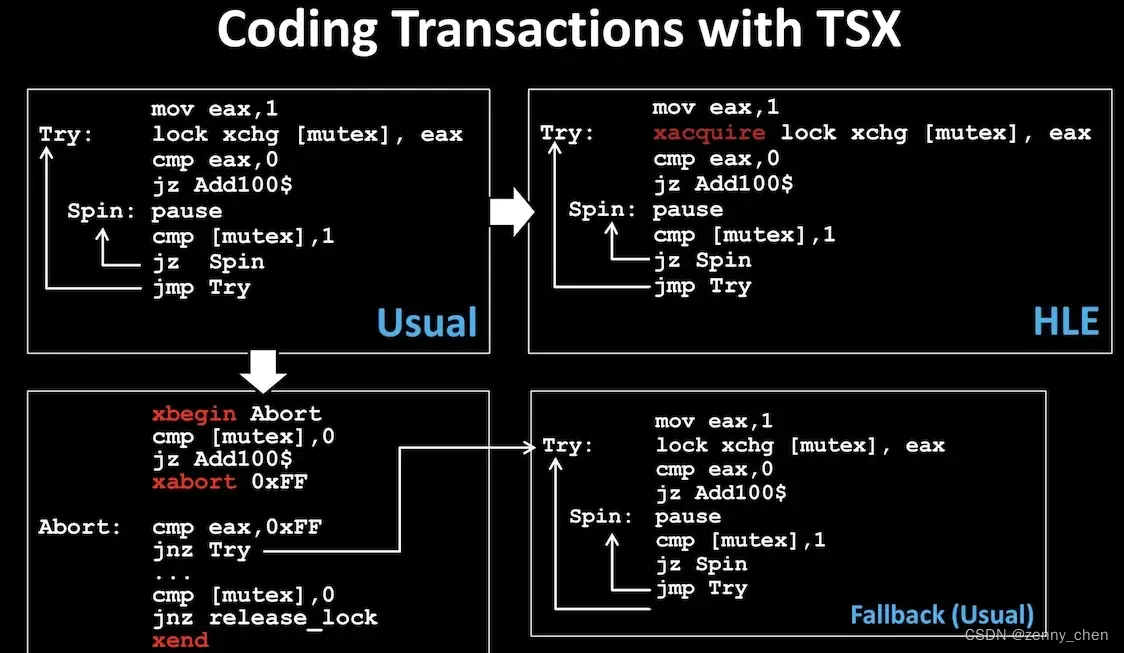
Atlas用了Intel TSX来完成这件事情。Intel TSX提供了HLE (Hardware Lock Elision)和RTM (Restricted Transactional Memory)两个编程接口,来提供一套简单但性能更优的临界区编程。
简单来说,Atlas用其中的RTM把解引用打包成一个事务,如果页面的内存不在本地,那么RTM会中止。
Egress
基于页面的换出,可以避免对象级LRU带来的高开销,以及避免对象驱除破坏空间局部性,同时其中I/O放大的关键问题由内存整合 (Move)解决。
Synchronization
- Object-in / Page-in (Ingress)
- Object-in / Page-out (Egress)
- Object-in / Evacuation (Move)
Synchronization of the Two Paths
同步问题比较细,Atlas用指针上的附加数据解决。有点像内核的设计。

第一类同步由于PSF只在换出的时候改变,因此不会存在。而同时访问相同的页面分别在Kernel和GC已经被解决(其他线程等一个线程)。
第二类同步问题通过强制页面不能在有对象正在其解引用域(dereference scope)的时候被换出来解决,类似rust,通过引用计数实现。但是不太优雅的是,可能很多页面上都有活跃对象,导致内存耗尽。解决方案是在内存压力下强制翻转PSF。(个人认为直接在分配的时候给PSF进行配额会更好,毕竟这个行为取决于程序员怎么写解引用域)。
第三类同步也还是通过引用计数实现。这个问题不大,因为移动是非强制的。
Dereference Scope and Barrier
AIFM的解引用域是粗粒度的,但是Atlas是细粒度的,每一个智能指针和一个解引用关联(而不是一个解引用域对应多个智能指针)。简单来说,就是AIFM的屏障发生在解引用域的生命周期(由对象的RAII决定)上,而Atlas的屏障发生在智能指针的“生命周期”(实则不是对象的生命周期)。
这个Trade-Off和粗/细粒度锁一样,但是Atlas认为它的优势能均摊这部分开销。
屏障的主要修改是引入RTM来解决两条路径的问题,这里省略。

Memory Management
由normal-object space, a hugeobject space, a metadata space, and an offload space组成,这部分比较细节,跳过。
- Object allocation
- Metadata allocation
- Object evacuation
- Computation offloading
0x04 Evaluation
基线采用AIFM和Fastswap,覆盖sequential, random, skewed, and mixed patterns几种内存模式。
- Memcached:采用了Cachelib(MCD-CL)的真实世界数据和YCSB的均匀数据(MCD-U)。MCD-CL具有高偏斜和Churn行为:Churn指工作集的热数据随时间快速变化;而MCD-U完全随机,没有偏斜或热数据。
- 图系统:GraphOne和Aspen的工作集不断变化,考察调节数据分布的能力。
- 数据处理系统:Metis和DataFrame,具有相变行为,考察路径切换。
- WebService:混合访问。
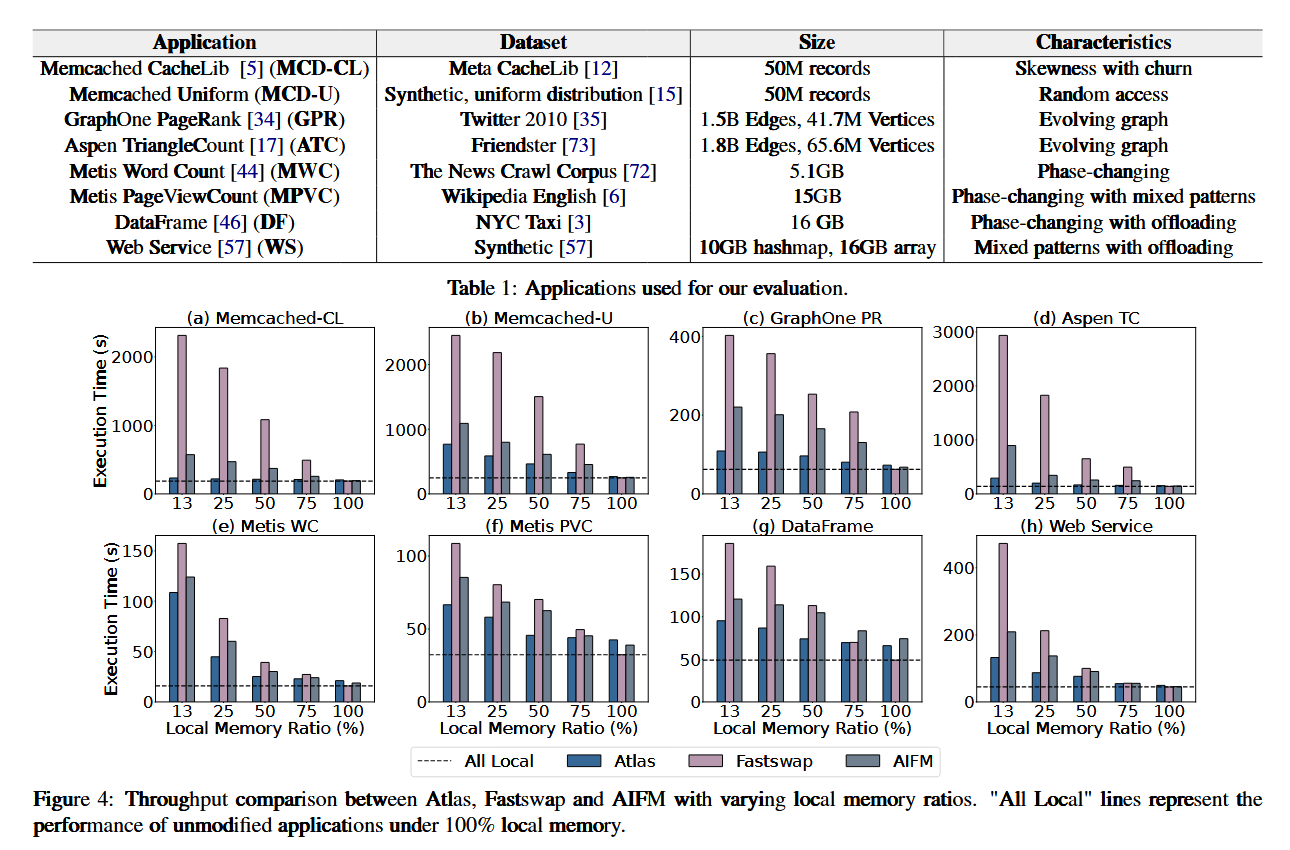
其余测试项目包含Throughput和Latency。最后进行了性能拆解测试。

0xFF Appendix
Intel TSX
举个例子,考虑一个事件:
|
|
如果用一个粗粒度锁来保护,这样Overhead比较小,但是这个事件内部的操作只能串行执行。
如果用一个细粒度锁来保护,这样事件内仍然可以并行,但是Overhead比较大而且编程复杂度会提高,比如可能有死锁问题,比如考虑:
|
|
可能出现死锁。
TSX的作用是,优化粗粒度锁下的假冲突,以释放事务中并行执行性能。这玩意逻辑上是一把粗粒度锁,但是实际上是硬件自动检测操作冲突,从而保证原子性。